Designing a solution for searching and filtering results in a high-volume table.
Navigation
1. Overview
The data-intensive product I worked on included tables with millions/billions of rows. Searching in these tables was slow and resource-intensive. This case study presents a solution to enhance the user experience when searching in high-volume tables.
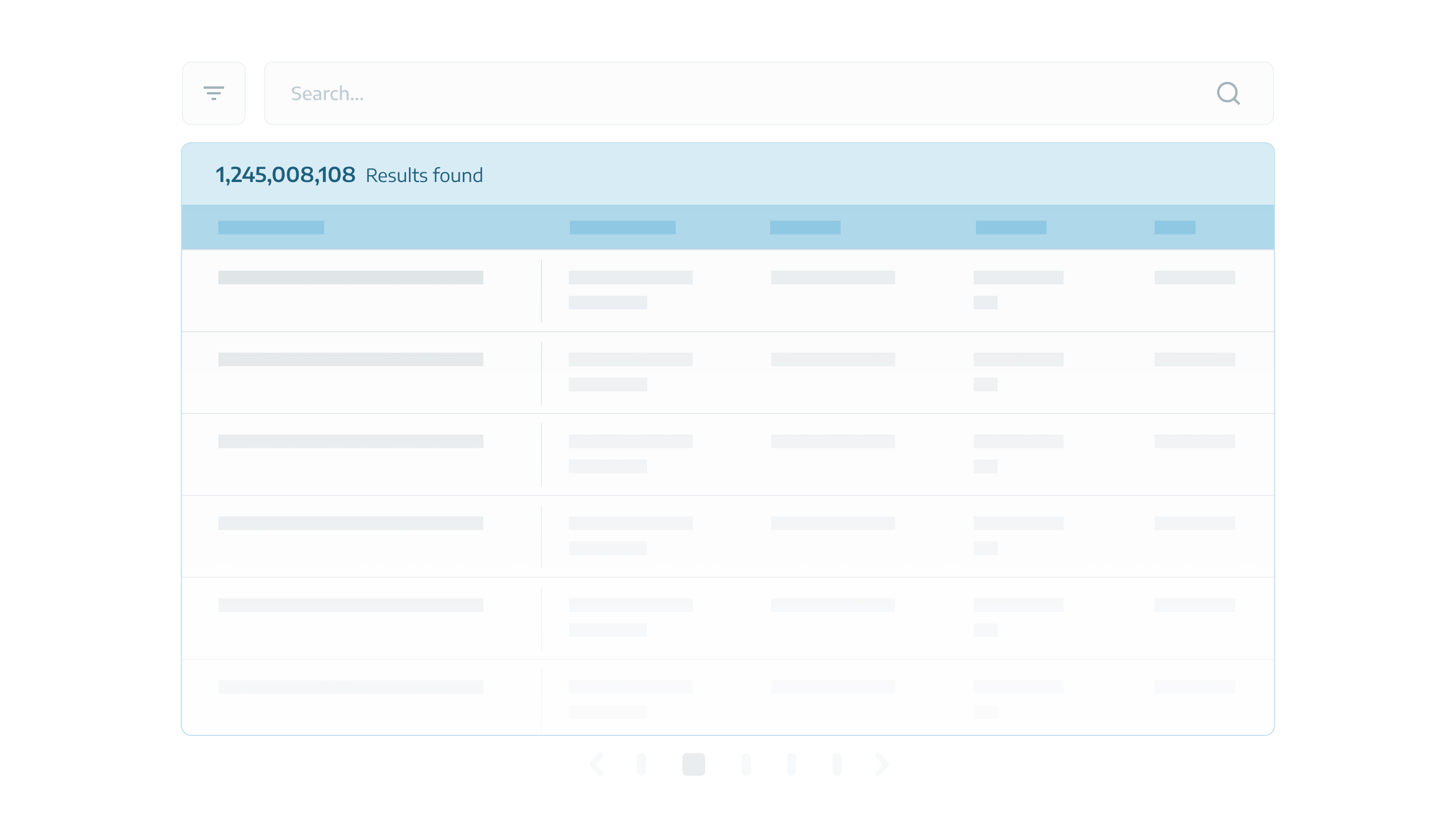
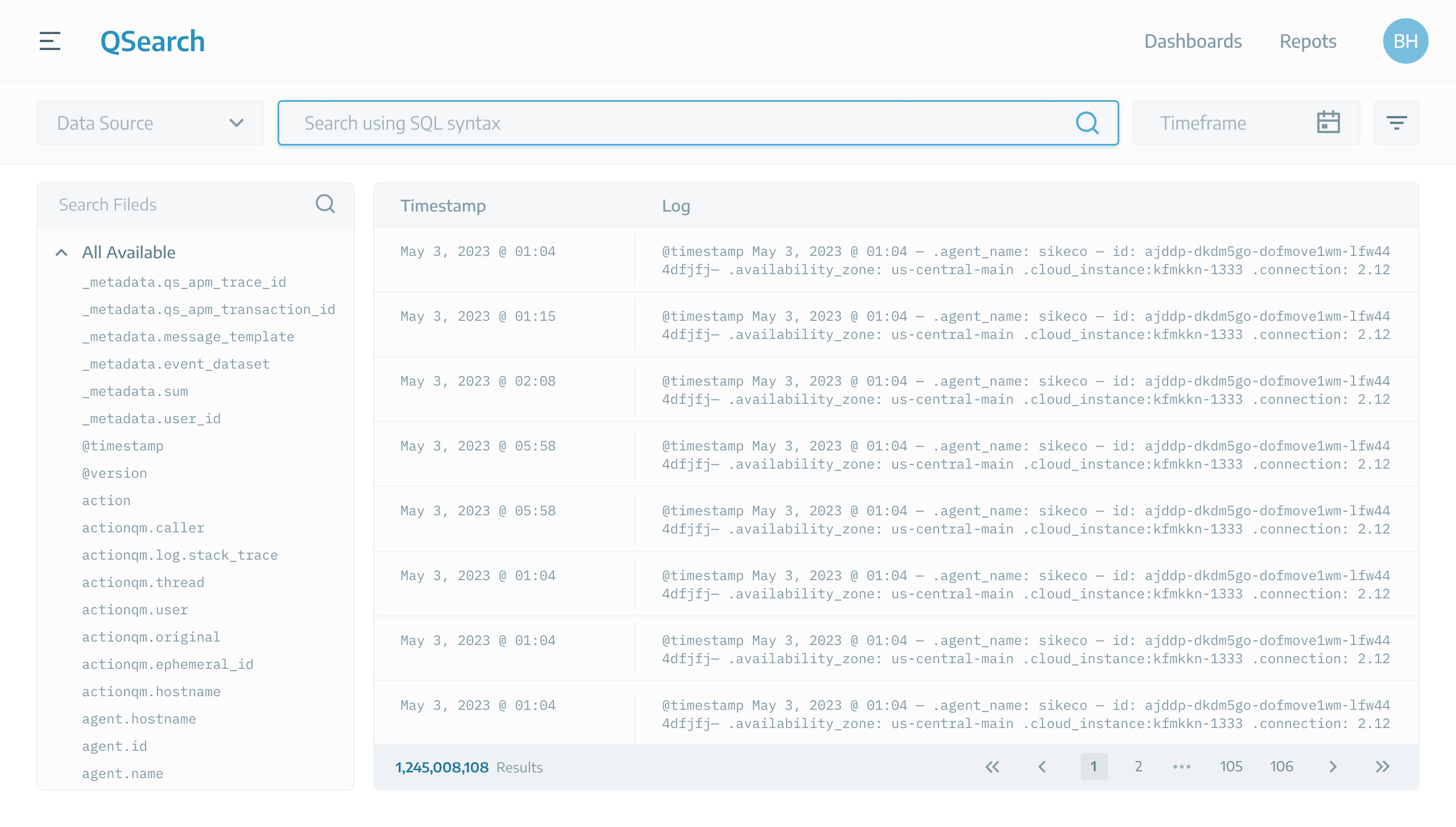
A sample high-volume table with over a billion rows.
This case study is focused on the following skills:
Problem Solving
User Research
Collaboration with Engineers
Interaction Design
Requirement Analysis
Iterative Design Process
2. Context
2.1. Role & Responsibilities
Role
Senior UX Designer
Team size
+20
Duration
2018-2021
Employer
A leading corporate in the field of cyber-security.
Responsibilities
Fixing UI/UX issues and designing new features.
2.2. Product
Product Type
An enterprise web application with a highly flexible and complex interface.
Product
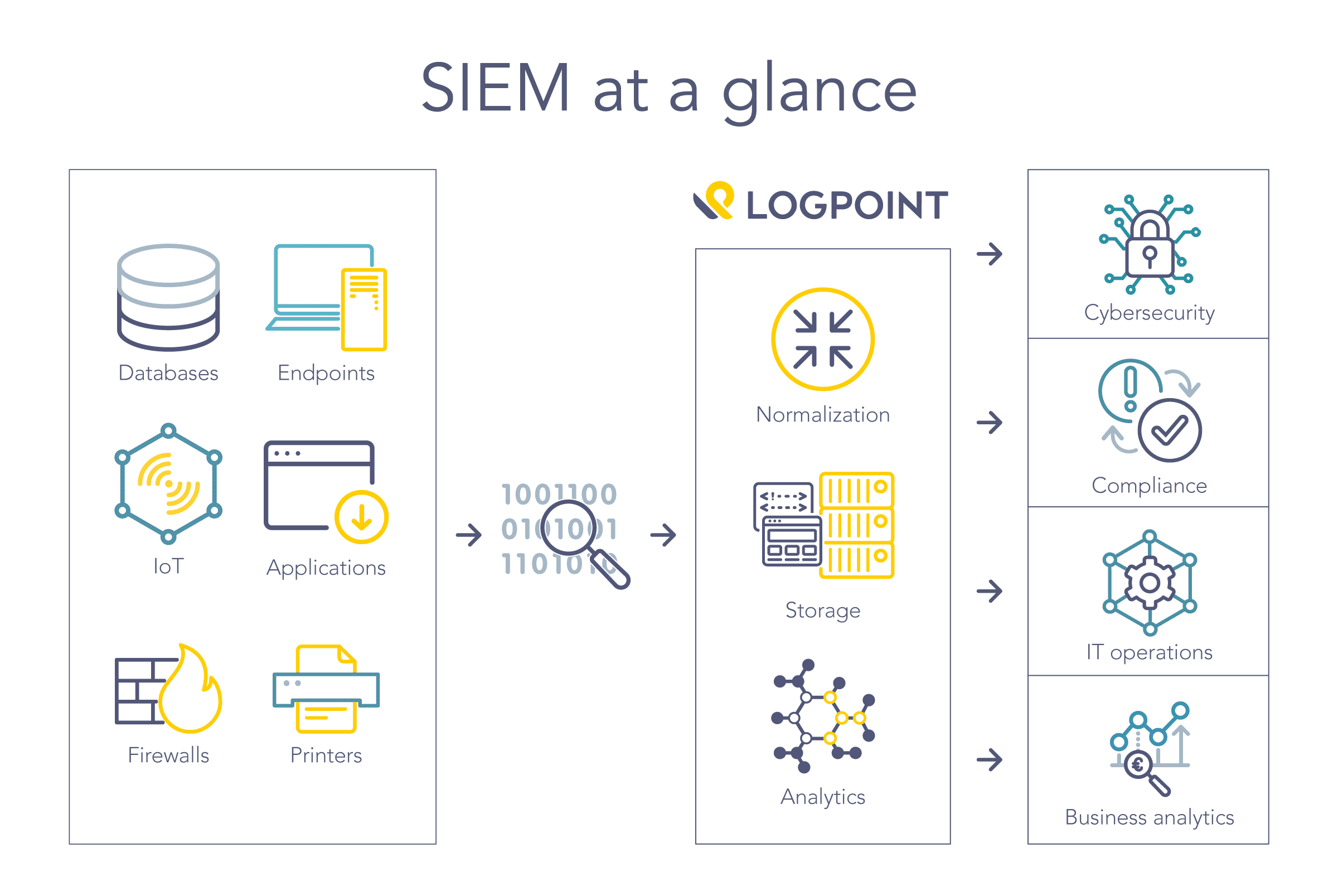
SIEM (Security Information and Event Management)
SIEM is used centralising security logs from various sources, and providing real-time monitoring, detection, and response to security threats.
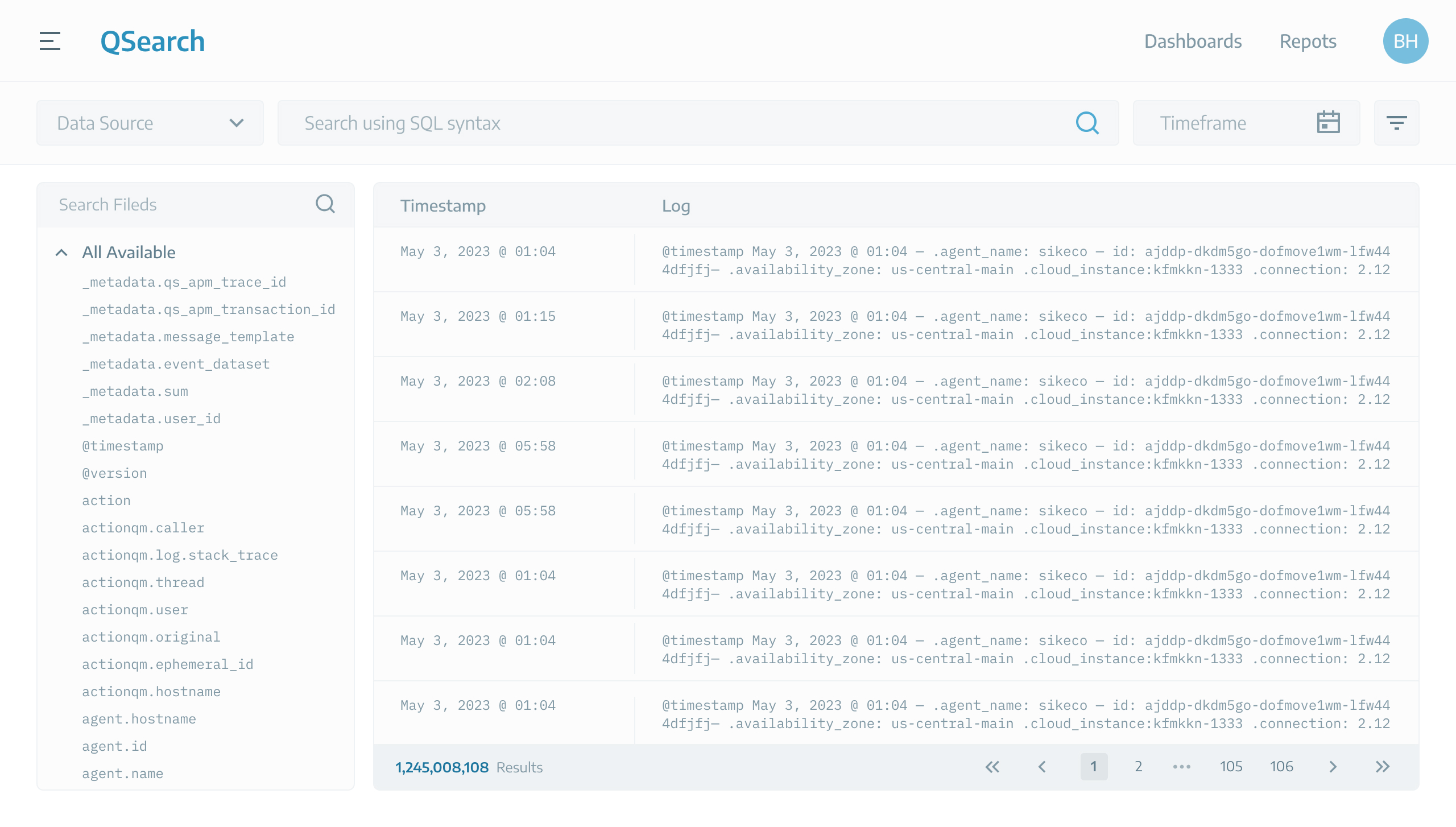
Screenshot from Splunk - A leading SIEM
SIEMs are complex products that contain several components. Among them, there is always a “Search” page where we show logs. This table can consist of millions or billions of rows.
2.3. Users & Usage
There are several user types dealing with this system. For this case study we’re focusing on this persona.
One of the personas - Already existed in the project.
A sample routine usage of the system by this user is:
Upon receiving a threat notification, these professionals refer to the search page to identify potential footprints of invaders.
3. Problem
The users search and filter among billions of results in this table to get to specific rows. They use an advanced search tool which is located on top of the table.
Advanced search and filtering tool.
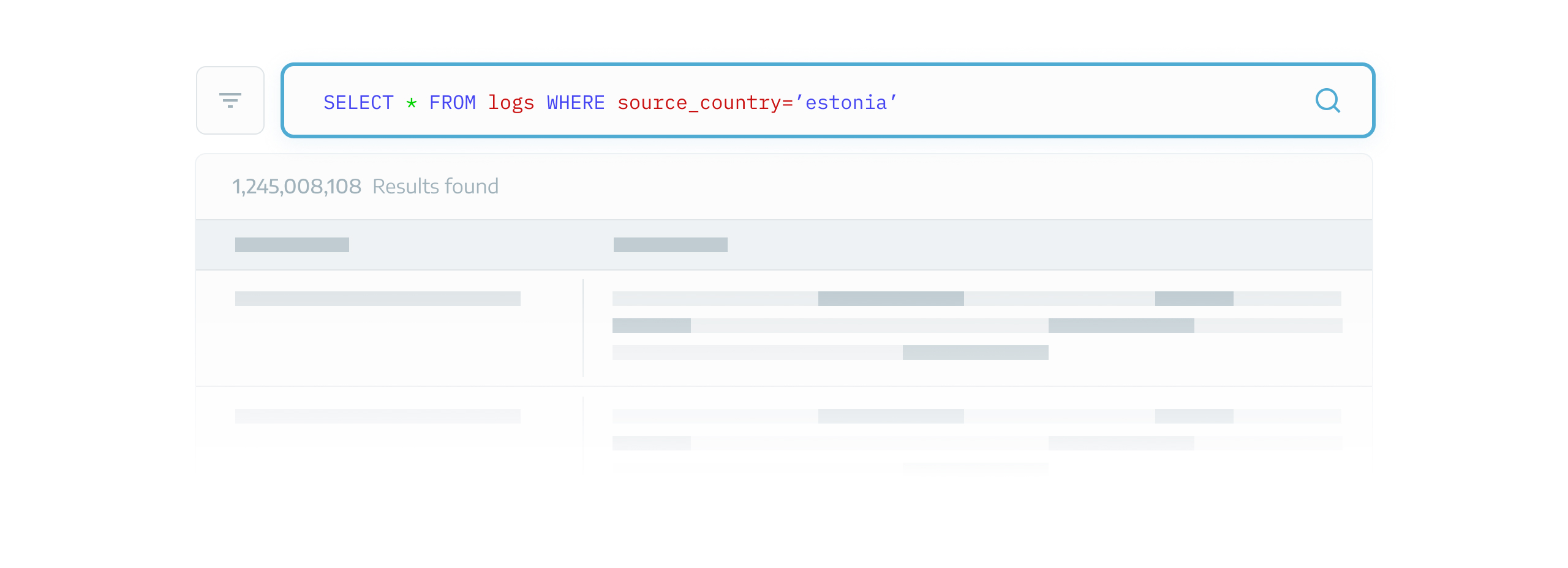
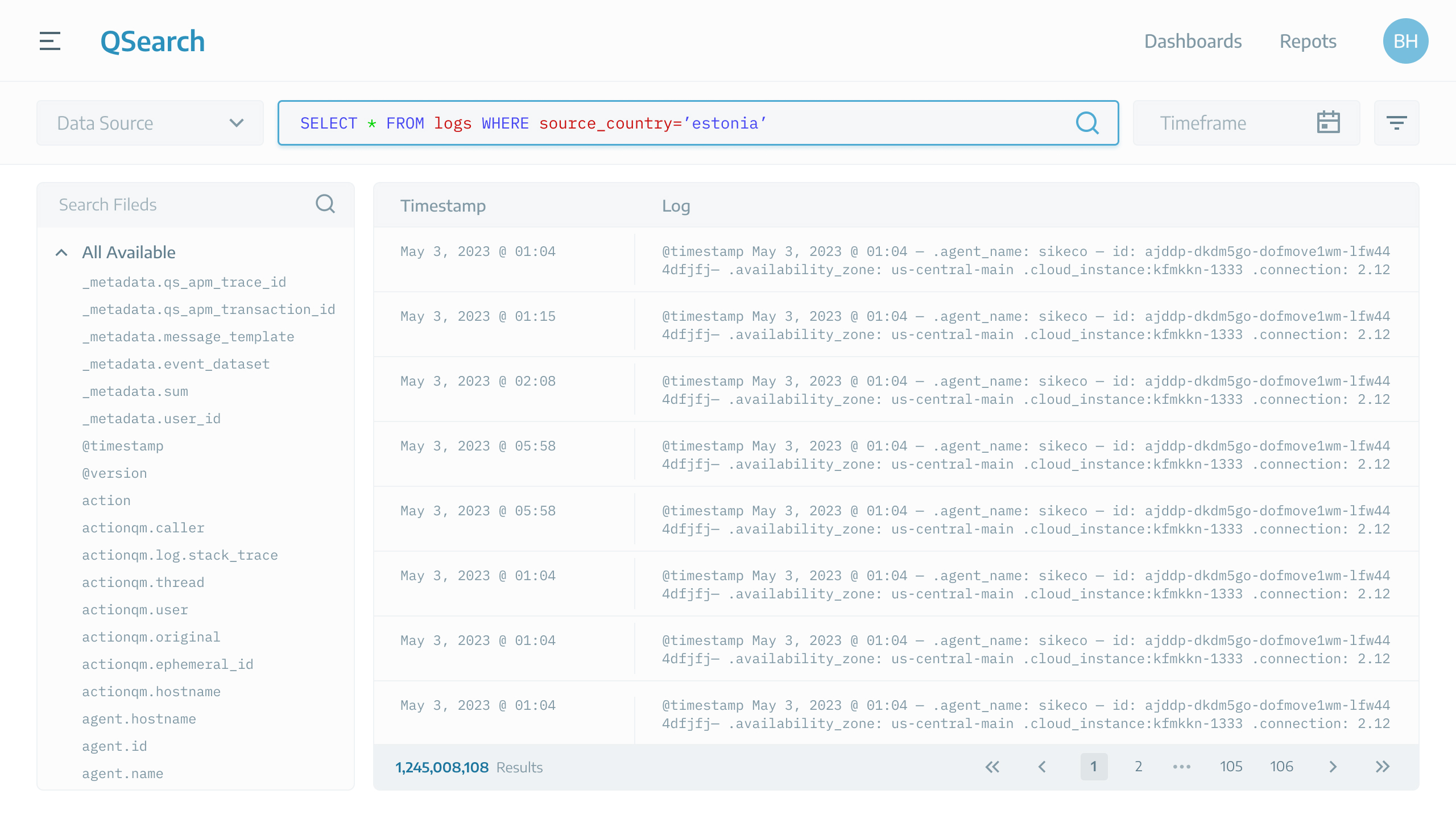
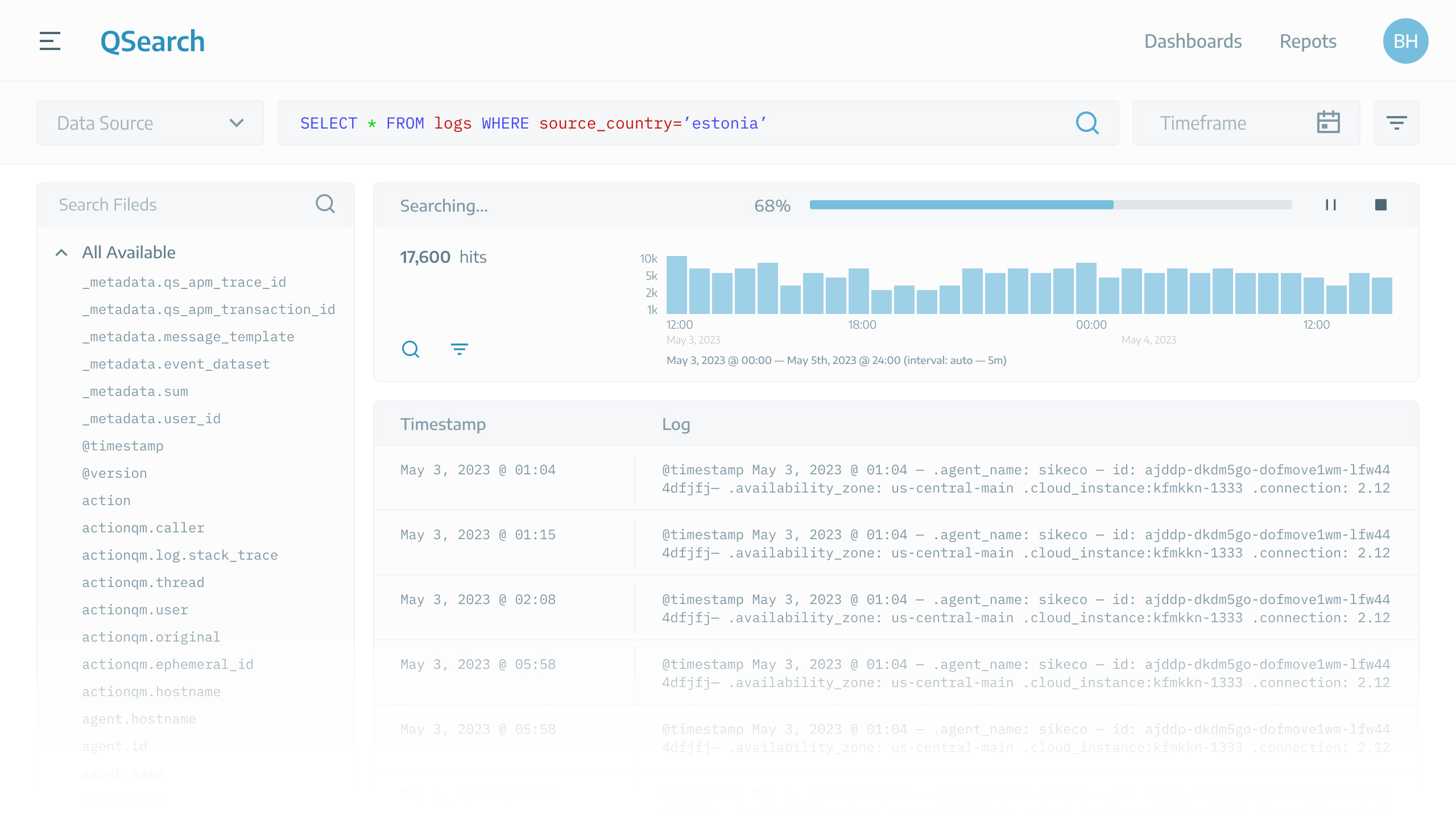
Let’s say user suspects the threat is coming from Estonia. Therefore, he wants to view logs originating from Estonia, so he searches as follows:
Sample search criteria defined by user.
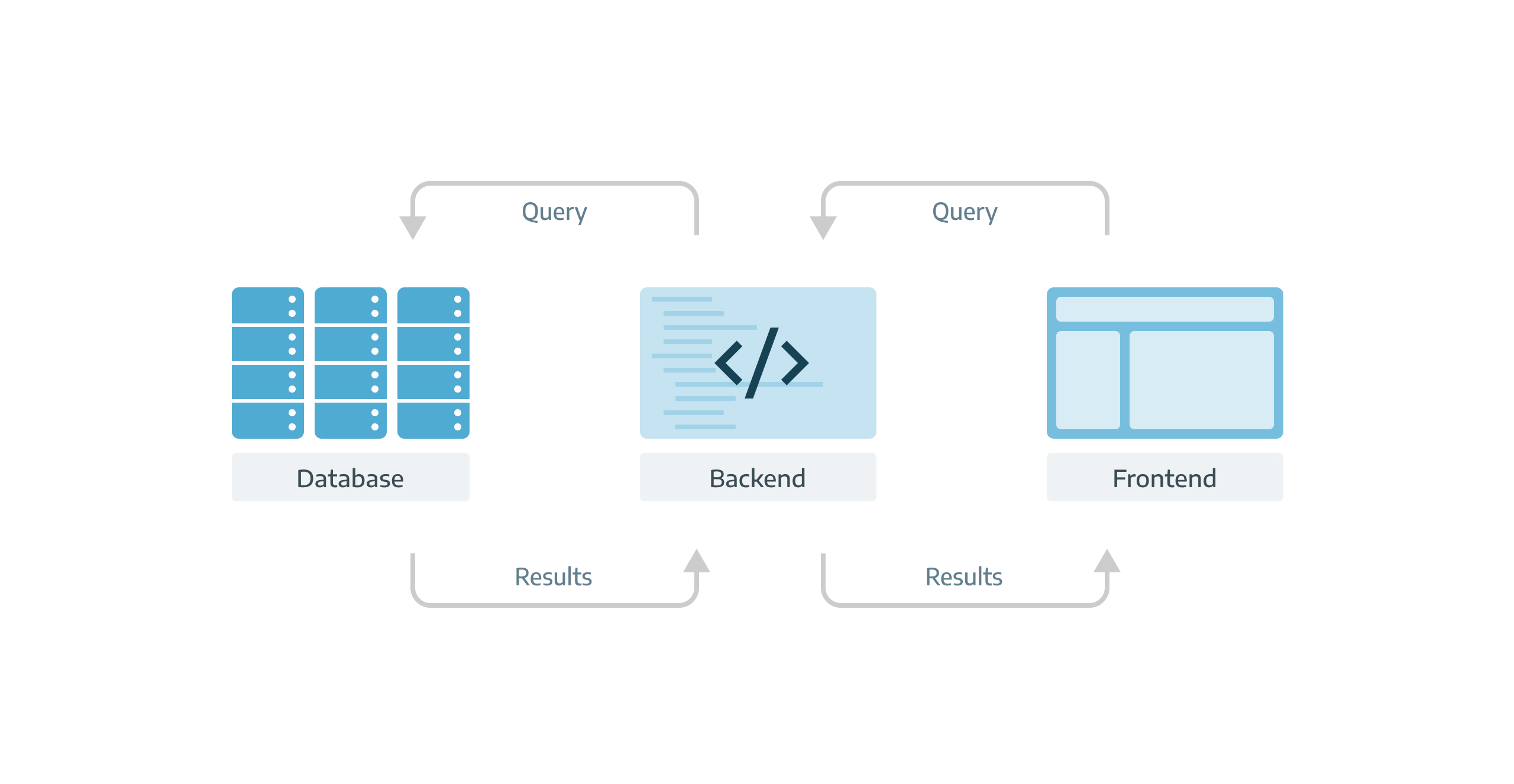
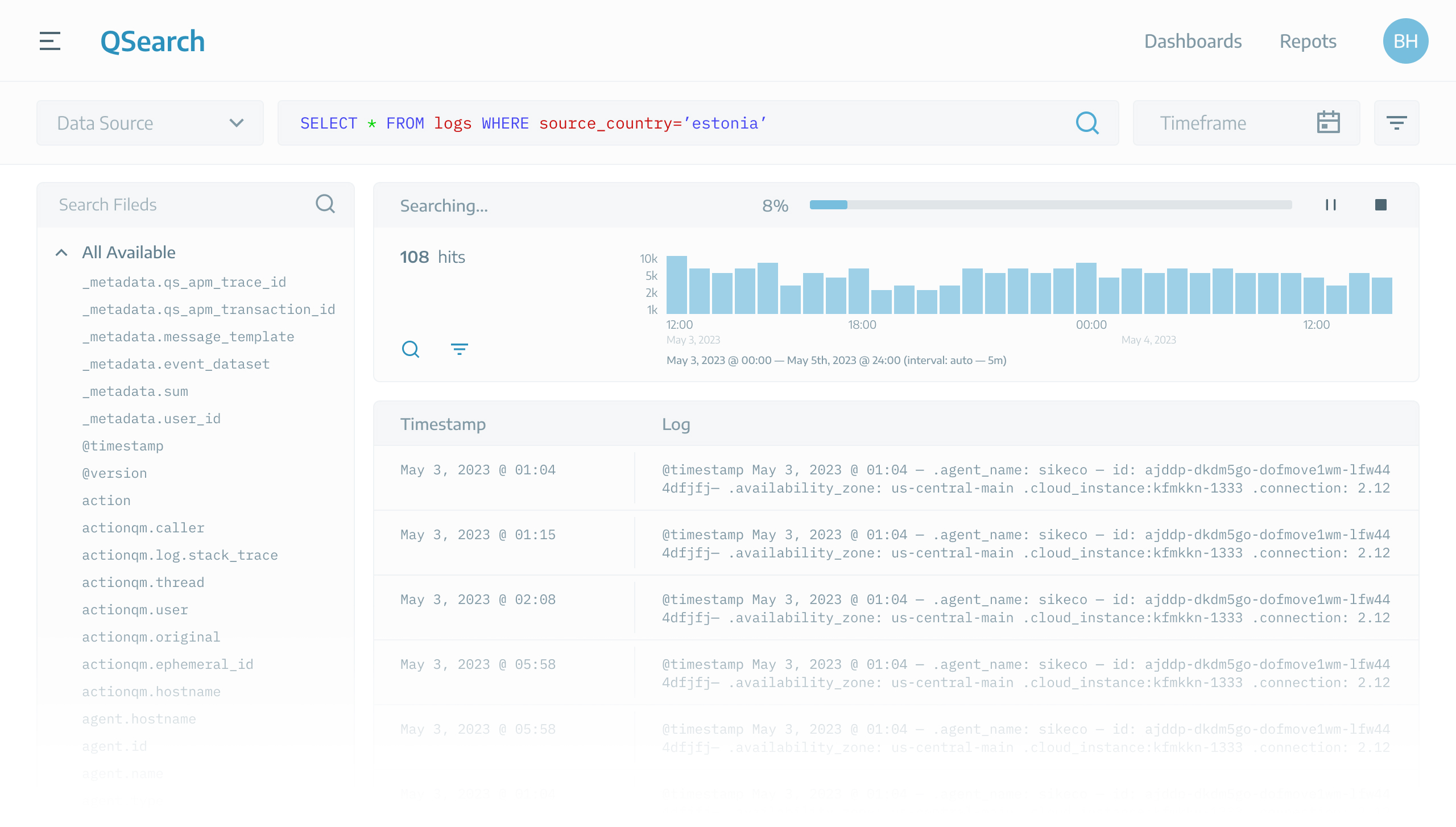
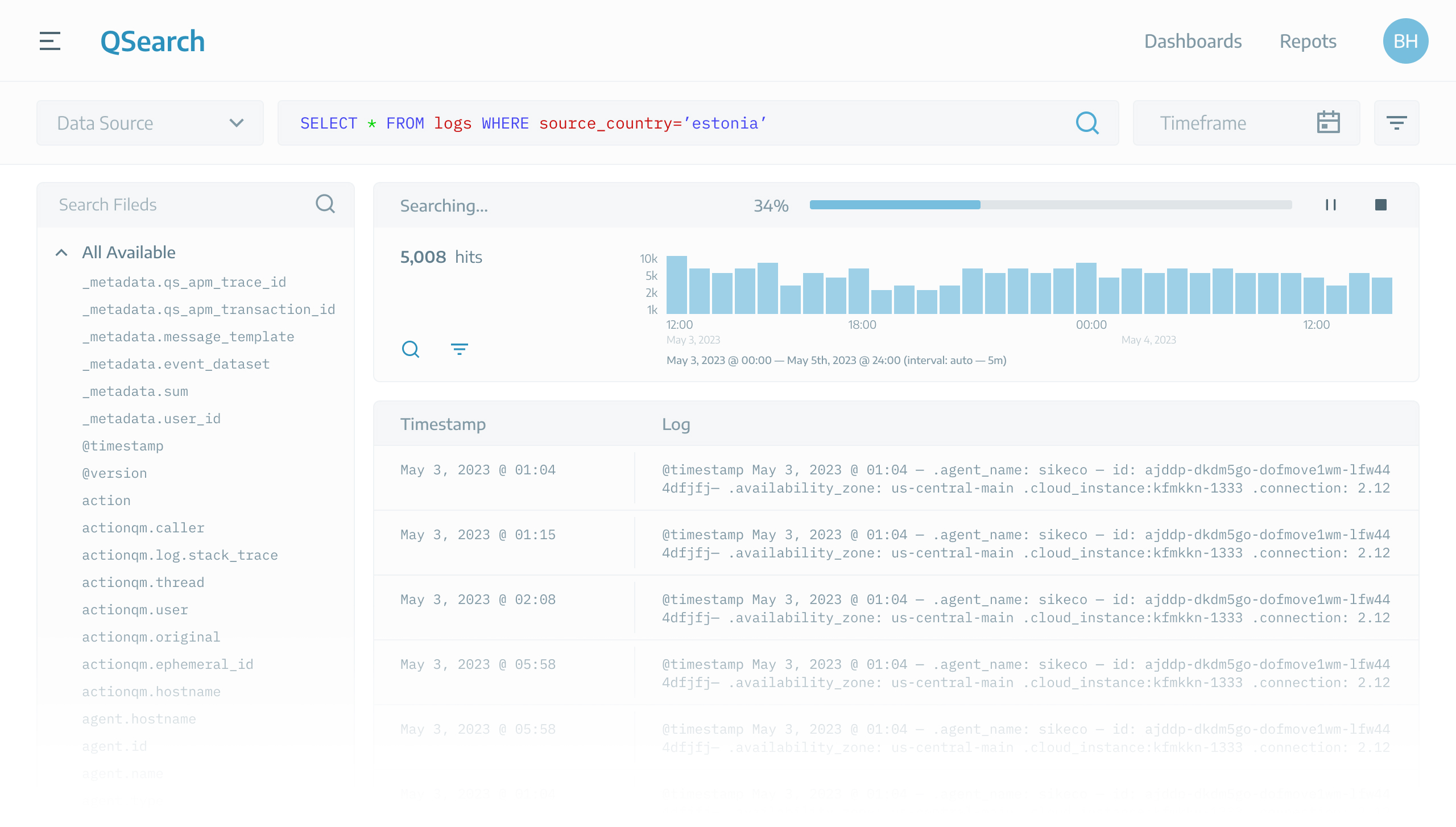
User initiates the search process and system entails the following steps to present the search results:
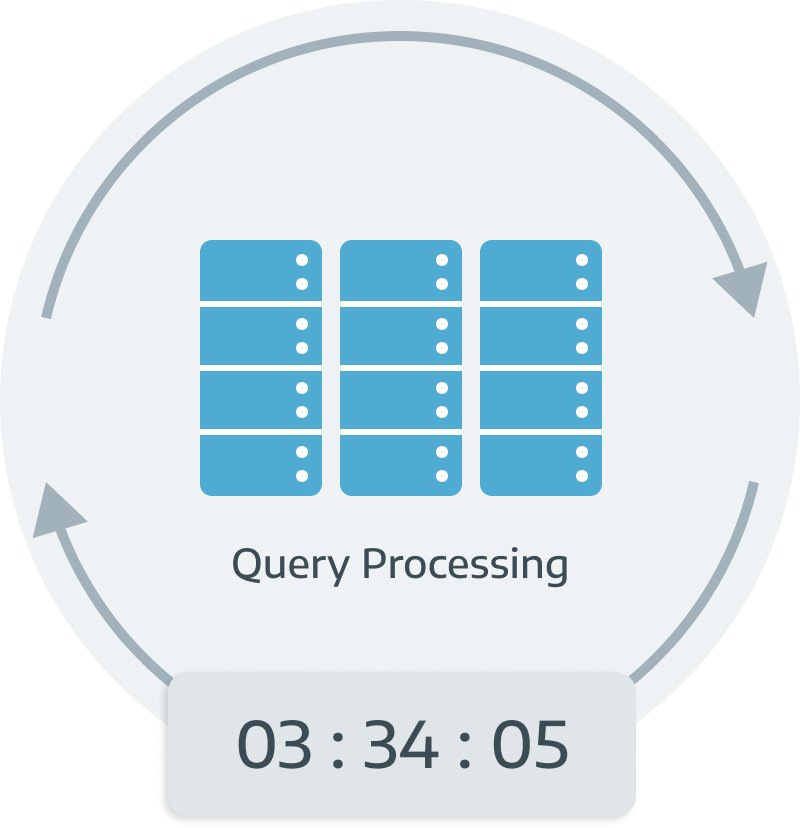
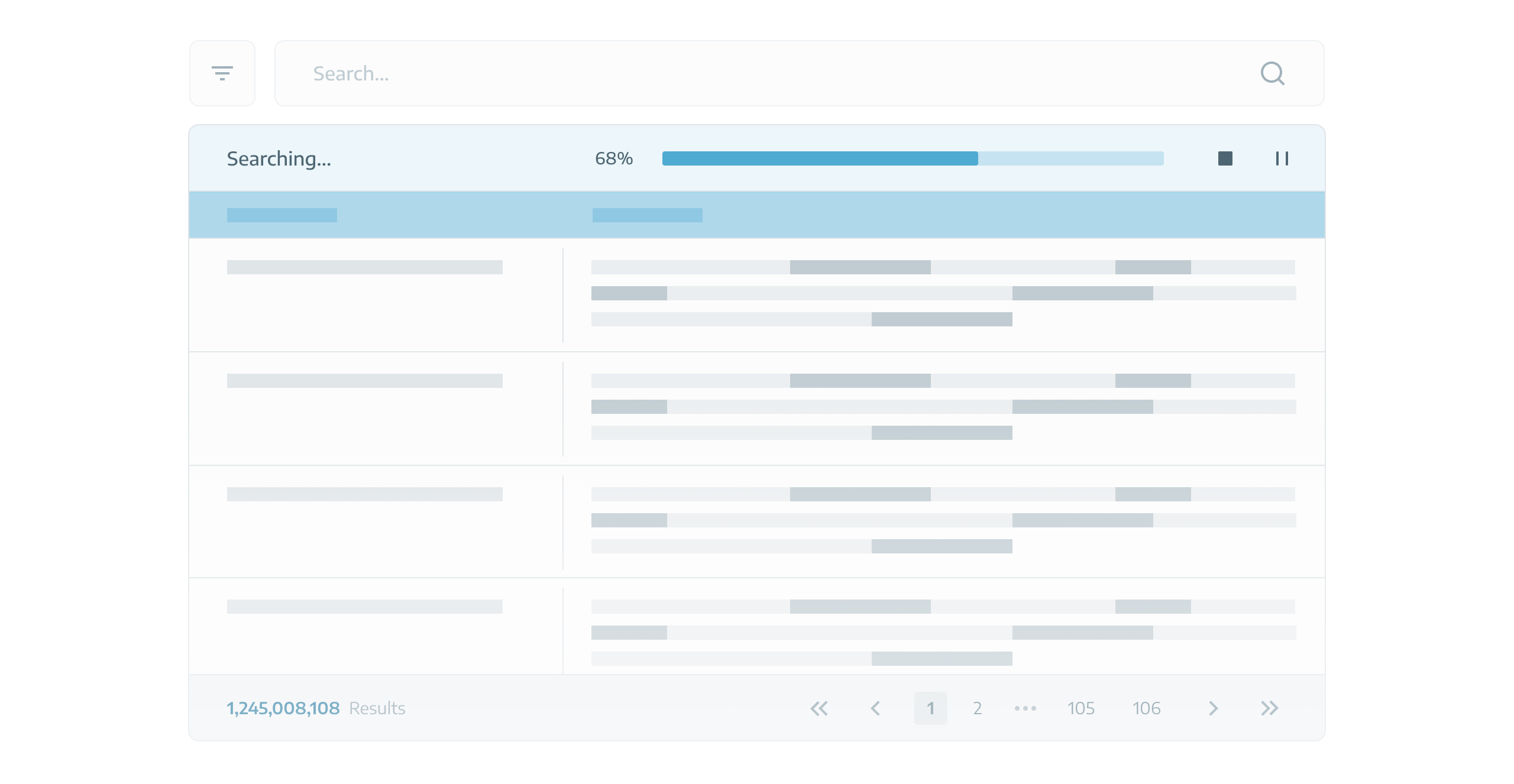
Traversing a database with billions of rows necessitates substantial time and resources. Therefore, users may experience wait times ranging from minutes to hours to obtain the results.
Time-consuming
Ranging from minutes to hours.
Resource-intensive
Clients had to keep adding resources to their servers.
This is what user see during the search process:
4. Constraints
Initially I tried to understand the constraints and limitations.
Increasing Resources?
Is it possible to request clients to allocate additional resources in order to enhance the search performance?
Improving the Technologies?
May we utilise more advanced technologies, such as specialised databases for time-series data?
After discussing with the project manager and engineering lead, it became evident that these are not feasible options based on our circumstances.
Every real-world problem comes with lots of constraints.
5. User Research
At this point, I was struggling with how to make the search function faster without the option to upgrade our existing technologies or allocate additional resources. Then I noticed:
"making search function faster" is a solution, not a requirement. Then what's the requirement?
Therefore, to better understand the needs of the user I performed some user research.
5.1. Method
Unsupervised user behaviour observation at customer environment with 9 users.
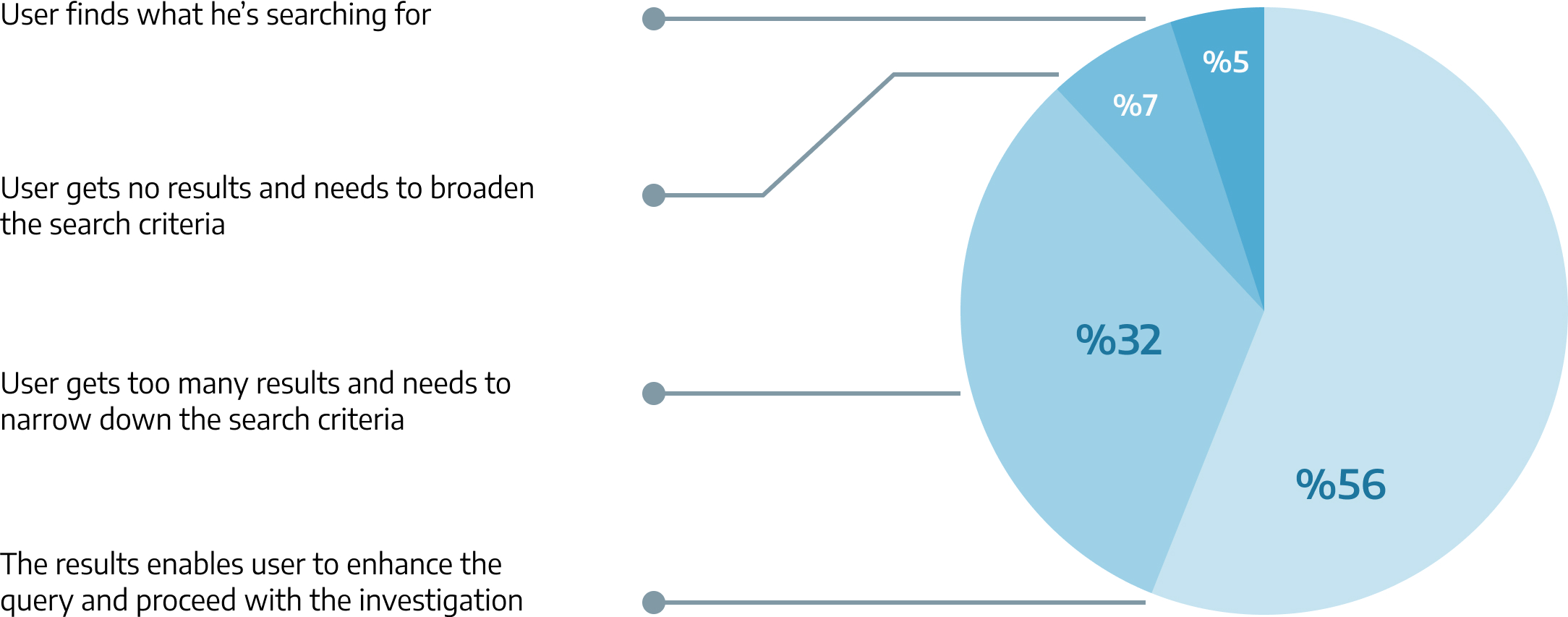
5.2. Observations
I observed the users search behaviour and figured out that this is what happens when a user runs a search:
In 95% of cases, users do not find the result in the first search.
On average, users run 6 searches before they find what they are looking for
5.3. Result
Based on the aforementioned observation, I came to a driving result:
Users do not need ALL results
before they deciding about their next search criteria.
This key moment in the design ticket revealed that the primary objective is not to increase the speed of the search function, but rather to expedite users’ access to the final results.
It became apparent that users were spending excessive time waiting for results in their first searches that they don’t need.
6. First Iteration
Considering that users conduct multiple searches to get to the final results + They do not require complete results from previous searches to determine their next search, I came with the first hypothesis:
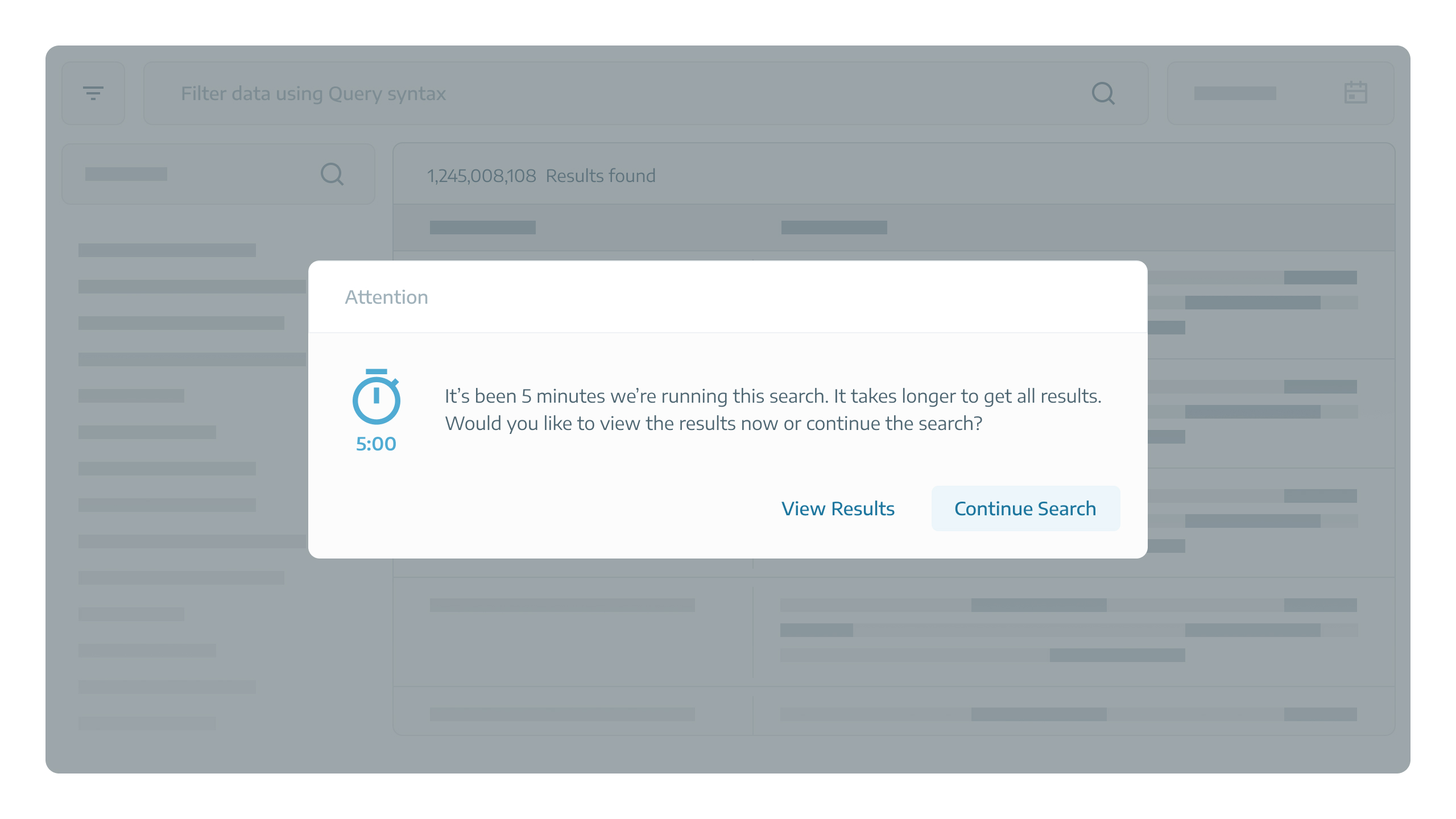
We can set a time threshold for query execution. The system runs the query for a maximum of X minutes. Then, the user is given the option to continue with the query or view the available results.
While this approach may initially seem acceptable, further investigations and discussions showed that it only covers a part of use cases due to the fixed threshold.
7. Second Iteration
Refining the first hypothesis, I came with an enhanced version of it. My seconds hypothesis was to make search real-time instead of setting a fixed threshold.
If we can display search results as soon as the database discovers them, the user can quickly create their next search and ultimately reach their goal faster.
8. Feasibility Check
But, is this hypothesis possible from the technical point of view?
Is it technically possible to retrieve the data from the database in real time?
To figure this out, I had several discussions with relevant people from our team.
Head of Engineering
Project Manager
DevOps Engineer
Lead Front-end Dev
Nonetheless, we have identified certain limitations in this approach, particularly with non-streaming operators like:
Nonetheless, we have identified certain limitations in this approach, particularly with non-streaming operators like these:
Order By
Groub By
Hash joins
Intersect
SELECT DISTINCT
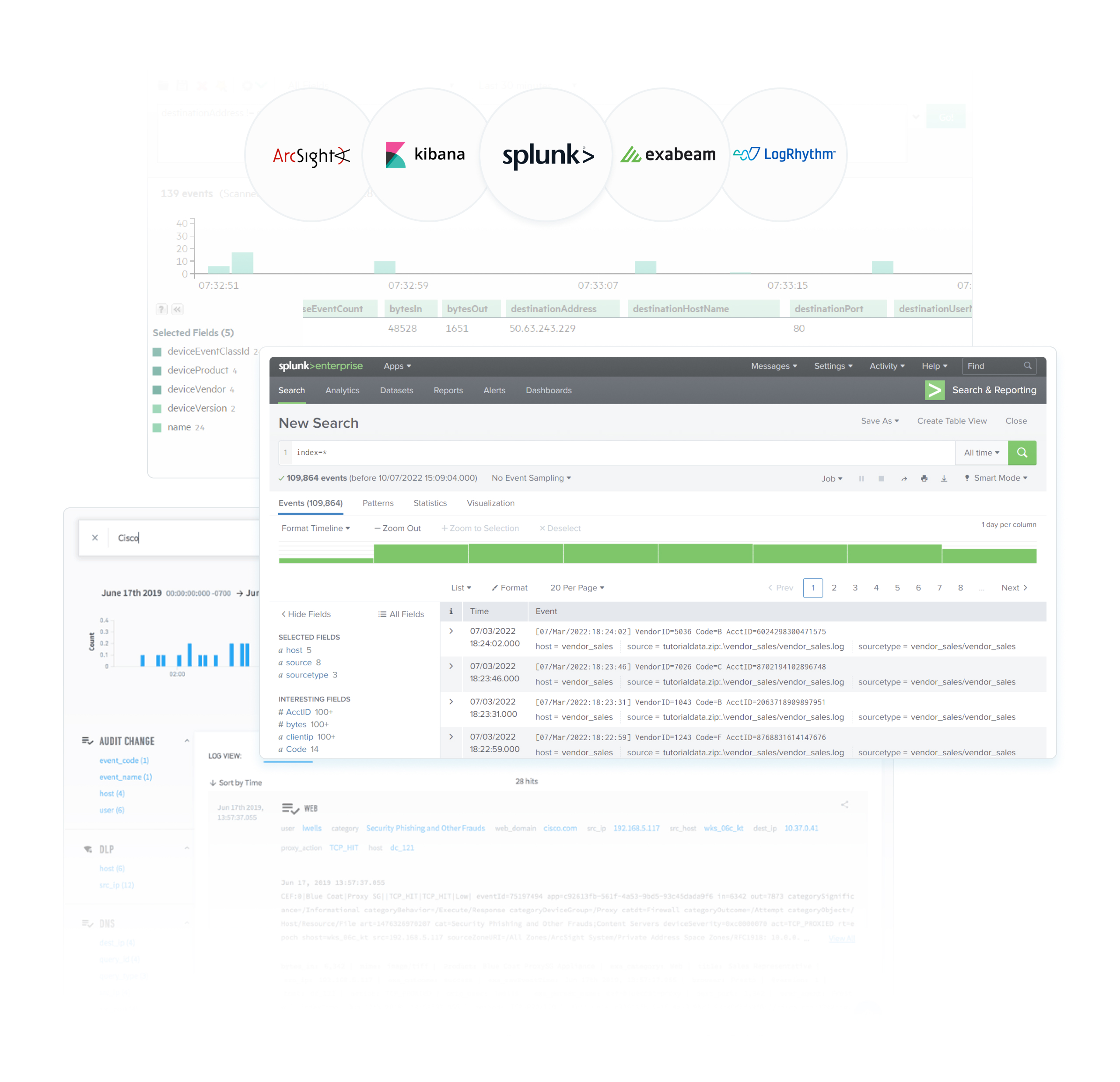
9. Competitor Audit
Subsequently, a comprehensive analysis was conducted on our direct and indirect competitors to gain inspiration in terms of design and approach. The following products underwent thorough investigation:
10. Design
10.1. Sketching
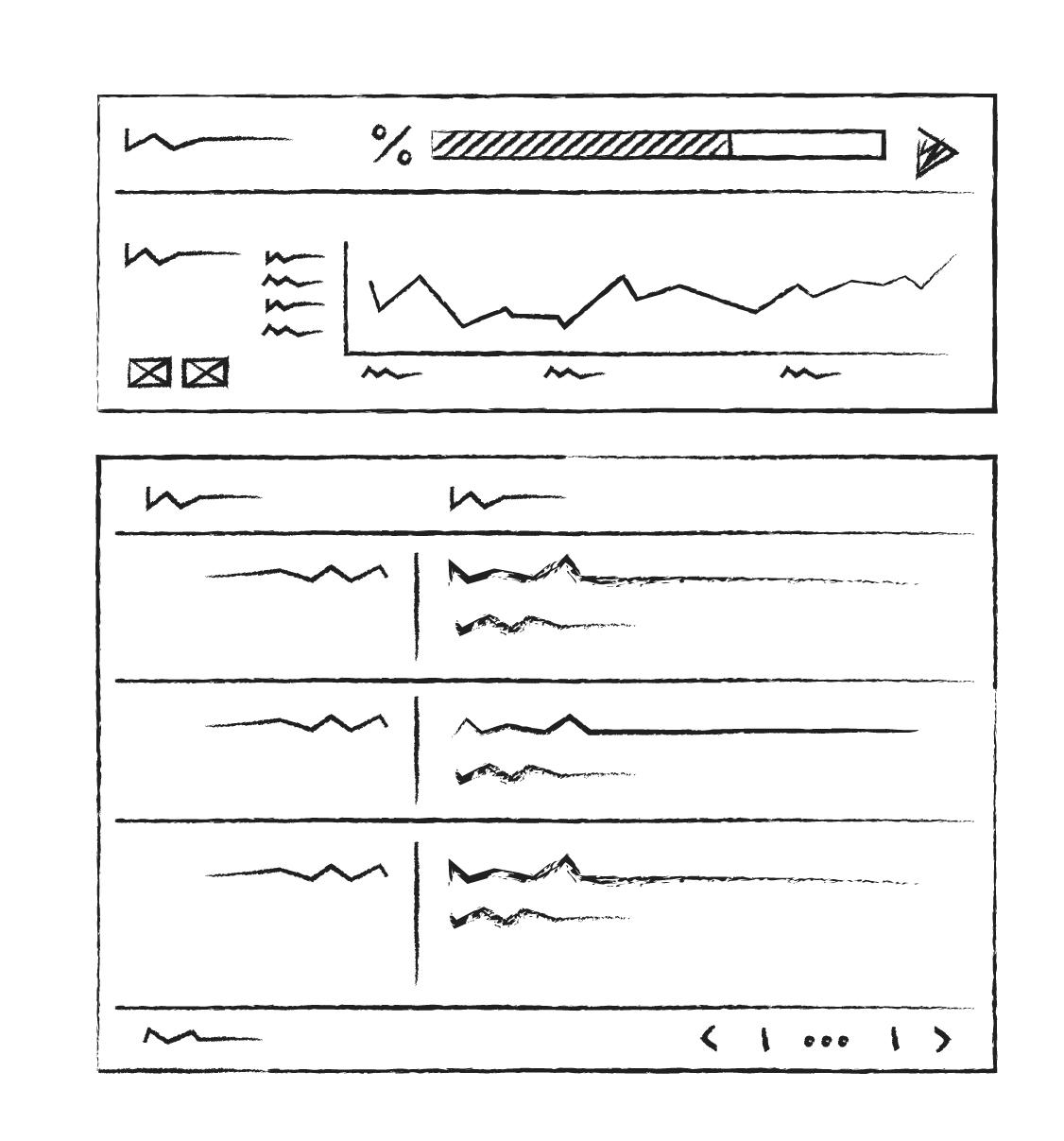
Here are some of the sketches created in early stages of ideation.
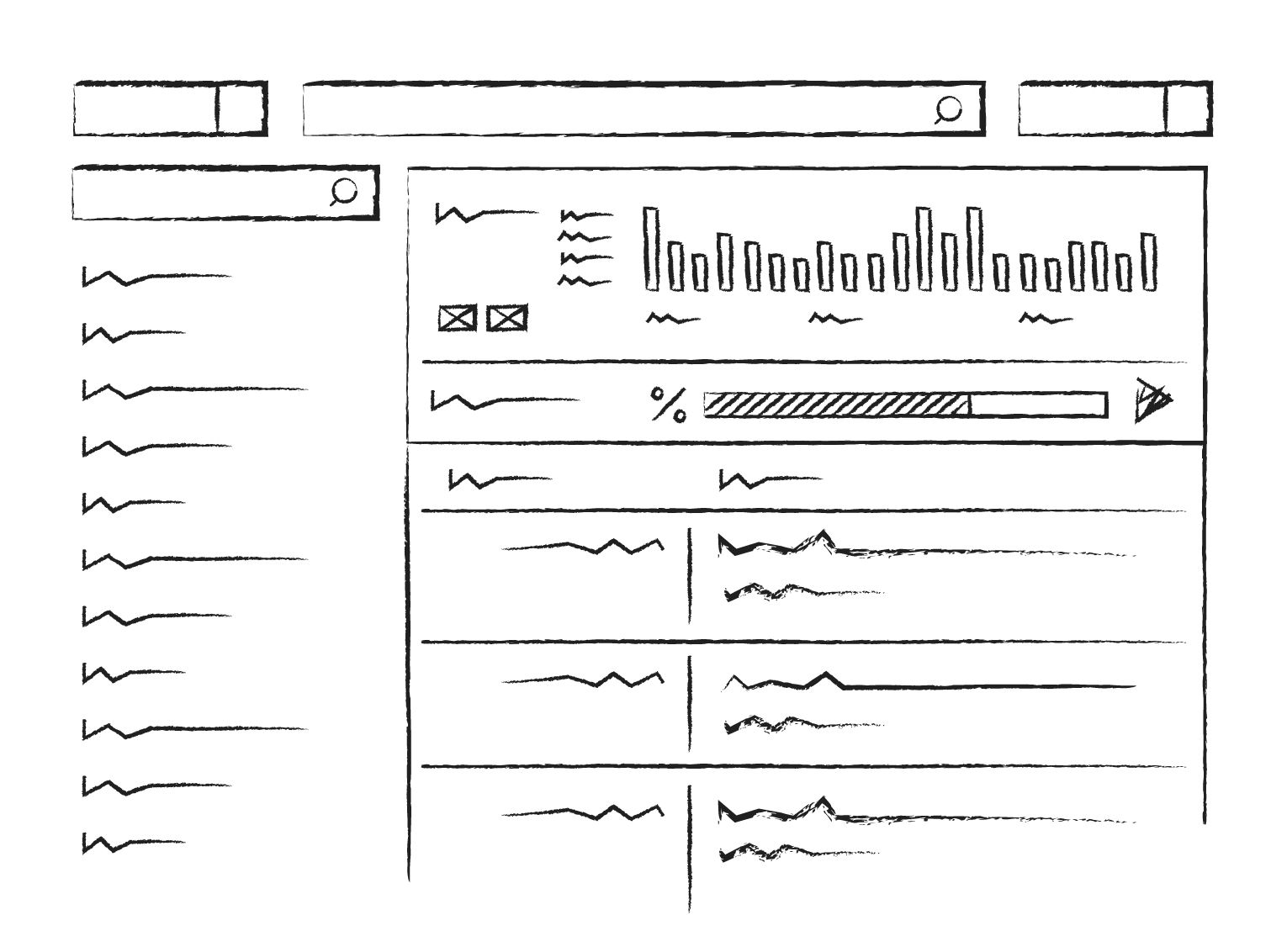
10.2. Mockups
Here are some of the mockups of the final product created in Figma. The product was re-branded to maintain NDA.
10.3. Prototype
This section allows you to view and interact with prototypes of both the current approach and the proposed approach. It enables you to experience firsthand how each feels, observe the differences, and identify the improvements made.
11. Evaluation
11.1. Gathering Internal Feedback
The above-mentioned prototype was used to present the idea, user flow, and interactions to our team for design validation and feedback gathering.
Small iterations and changes were made based on the feedback, and the solution was implemented by our development team with ongoing support from my side.
Subsequently, the solution underwent thorough testing by our QA engineers to ensure its functionality and performance.
If it takes 5 searches to get to specific results, and each search takes 15 mins to finish, and if user can decide about the next search criteria using the results retrieved in the first minute of search being running, the improvement would be as follow:
11.2. Testing with the End-user
First
The solution was tested with 9 users/orgs in their place.
Second
Every user was asked to run several searches based on their daily needs.
Third
We updated the application for their organisation on the same day.
Fourth
The exact searches were performed again using the new interface.
A total number of 180 searches were performed and the the results were recorded and is presented in the next section.
12. Outcomes
The outcomes for end-users and organisations based on initial round of tests were as follows in a nutshell.
For The End-user
83% Faster
In reaching the final results*
For The Organisations
21% Lower
system load on servers **
* On average. Based on 180 searches performed by 9 users. ** On average. Calculated for 9 organisations. System load (Unix) was recorded over one month of usage.
13. Challenges
Throughout the project, we encountered several challenges. Here, I will outline the top three challenges and then provide more details about one particular challenge and my approach to addressing it.
Highly technical knowledge was required
Users were not directly accessible
Too many constraints to be considered
To understand the problem technical aspect and develop a robust solution, I took the initiative to participate in a Splunk course voluntarily. This course provided valuable knowledge on how cybersecurity specialists effectively search through logs to uncover evidence.
13. Learnings
Throughout this extensive design ticket, I have acquired valuable insights. The most significant learning for me has been:






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}